
PRODUCT TRAINING · 内部培训
中科DPU WS5000 产品培训
全闪加速存储算力一体机 · 融合 AI 算力中心完整模块 · 面向全体相关团队

01
COMPANY & POSITIONING
公司与产品定位
从精密电子制造的传承者,到 AI 算力基础设施的建设者。
WHO WE ARE
深圳市中科航星科技有限公司 · 中科DPU
公司战略聚焦 AI 算力基础设施,以 存算分离 为核心技术路线,旗舰产品线为 中科DPU,核心型号 中科DPU WS5000(WS-HBMM5000) 全闪加速存储算力一体机。
约 10 年
持续研发积淀
技术/产品/制造风险已退坡
约 10 亿元
累计研发投入
公司自有历史投入口径
1,000 套/月
量产能力
立讯精密代工产线
2 套
现货样机
可即时送测

深圳 · 前海/河套 — AI 算力基础设施沃土

大模型时代的算力悖论:买了顶级 GPU,却在「等数据」
全国智算中心平均利用率不足 60%——算力被存储 I/O 拖累。模型加载、Checkpoint 读写、KV Cache 调度成为隐形瓶颈。

02
AI COMPUTING CENTER 101
AI 算力中心基础科普
先懂智算中心,再懂我们在其中的位置。本模块为科普口径,建立共同语言。
WHAT IS IT
什么是 AI 算力中心(智算中心)
AI 算力中心(智算中心)是为人工智能训练与推理提供大规模并行算力的专用数据中心,由四大要素协同构成——缺一不可、相互制约。
- 算力:GPU / NPU(如华为昇腾)集群,决定「能算多快」。
- 网络:高速无损网络(IB / RoCE),决定「卡间能否高效协同」。
- 存储:海量高带宽数据供给,决定「GPU 是否吃得饱」。
- 供电与制冷:电力与散热(PUE),决定「能不能持续、划不划算」。
智算中心:算力 · 网络 · 存储 · 供电制冷
NETWORK
网络层:无损网络与东西向流量
- 东西向流量:AI 集群里「卡与卡之间」的数据交换远大于「南北向」对外流量。
- 无损网络:InfiniBand 或 RoCE(RDMA over Converged Ethernet),低时延、零丢包。
- RDMA:远程直接内存访问,绕开 CPU 与多次拷贝,逼近本地访问速度。
- 中科DPU 的承载:以 NVMe-oF over RDMA/RoCE 把存储接入这张高速网,让数据「直达」。

RDMA/RoCE 高速无损互联织构
存储层:AI 算力中心的「隐形瓶颈」
传统 NFS/集中式存储带宽有限,GPU 频繁「等数据」。存储层级(显存→内存→本地盘→网络存储)层层下探,越往外越慢——而大模型恰恰要频繁穿越这些层级。

03
THE PRODUCT
中科DPU WS5000 产品深度
把存储从「配角」升级为「算力放大器」。
OVERVIEW
中科DPU WS5000(WS-HBMM5000)
面向 AI 训练/推理的 高性能全闪加速存储算力一体机。通过存算分离架构与端到端高速数据通路,使 GPU 集群摆脱「等数据」瓶颈,在 不改变上层框架 的前提下显著提升算力有效利用率、大幅降低数据中心总拥有成本。
全闪 EBOFNVMe-oF / RDMAGPUDirectKV Cache 加速国产可控开箱即用

中科DPU WS5000 全闪加速存储一体机

04
TECHNOLOGY
技术原理与架构
存算分离:把存储解耦成可独立扩展的全闪池,用高速无损网与算力池互联。
DISAGGREGATION
存算分离架构:算力池 ⟷ 高速网 ⟷ 全闪池
- 解耦:把存储介质从计算节点中拆出,汇聚为独立的全闪存储池。
- 互联:通过高速无损网络与 GPU 算力池相连,数据「直达」。
- 弹性:算力与容量 独立扩展,资源池化、高效共享。
- 无感:上层训练/推理框架无需改造,平滑接入。

存算分离:计算节点 ↔ NVMe-oF ↔ EBOF 全闪池
DOMESTIC
国产可控适配:契合自主可控大势
- 昇腾深度适配:面向华为昇腾等国产算力底座深度优化。
- 广覆盖:主流加速卡适配率 90%+。
- 在测拓展:AMD、超聚变平台适配测试推进中(以最终报告为准)。
- 信创友好:满足政企/智算中心自主可控诉求。
面向国产算力底座的存算分离适配

05
INDEPENDENT VALIDATION
第三方实测验证
北京信息科技大学 · 华为昇腾 Atlas 910B 平台 · 7 项指标全面领先。
SETUP
可复现的第三方实测
- 测评方:北京信息科技大学(国家级院校,独立第三方)。
- 平台:华为昇腾 Atlas 910B。
- 对照基线:NFS 网络存储(NFS over TCP,10GbE)。
- 中科DPU 链路:NVMe-oF over RDMA/RoCE(2×200GbE,线速 50GB/s)。
- 覆盖:推理加载/服务、训练读写、Token 效率,共 7 项关键指标。
北京信息科技大学 · 昇腾 Atlas 910B 实测
06
CUSTOMER VALUE
客户价值与单位经济
为客户创造可量化的价值:更低 TCO、更高 GPU 投资回报。

07
COMPUTE CENTER BUSINESS
AI 算力中心业务
不止卖盒子:从一体机,到算力服务与智算中心共建。
智算中心共建:从供应商到合伙人
依托深圳前海/河套区位与政策,参与 智算中心共建——把 WS5000 作为存储算力底座,与算力运营方共享长期算力服务收益。
RETROFIT
存量改造:轻资产、可复制
- 不停机:在役集群无需更换 GPU,加速套件接入即提速。
- 提产出:改造后 Token 有效产出提升约 30%(保守口径)。
- 分成制:在增量产出价值中分成约 15%,与客户利益绑定。
- 可寻址:全国智算中心利用率不足 60%,存量提效空间巨大。
盘活存量算力:轻资产分成模式

08
ECOSYSTEM & SUPPLY
生态与量产
确定性来自哪里:已验证、可量产、有生态。
PARTNERS
生态与适配版图
华为昇腾国产 GPU 90%+AMD(在测)超聚变(在测)立讯精密代工北京信息科技大学
对外口径纪律
已落地 与 推进中 必须分清楚:实测/量产是已落地;AMD/超聚变是推进中(在测)。实事求是是我们最强的信任资产。
已定型量产 · 立讯精密代工

09
MARKET & ROADMAP
市场与路线图
空间足够大,节奏足够稳。
MARKET
AI 存储:高速增长的核心赛道
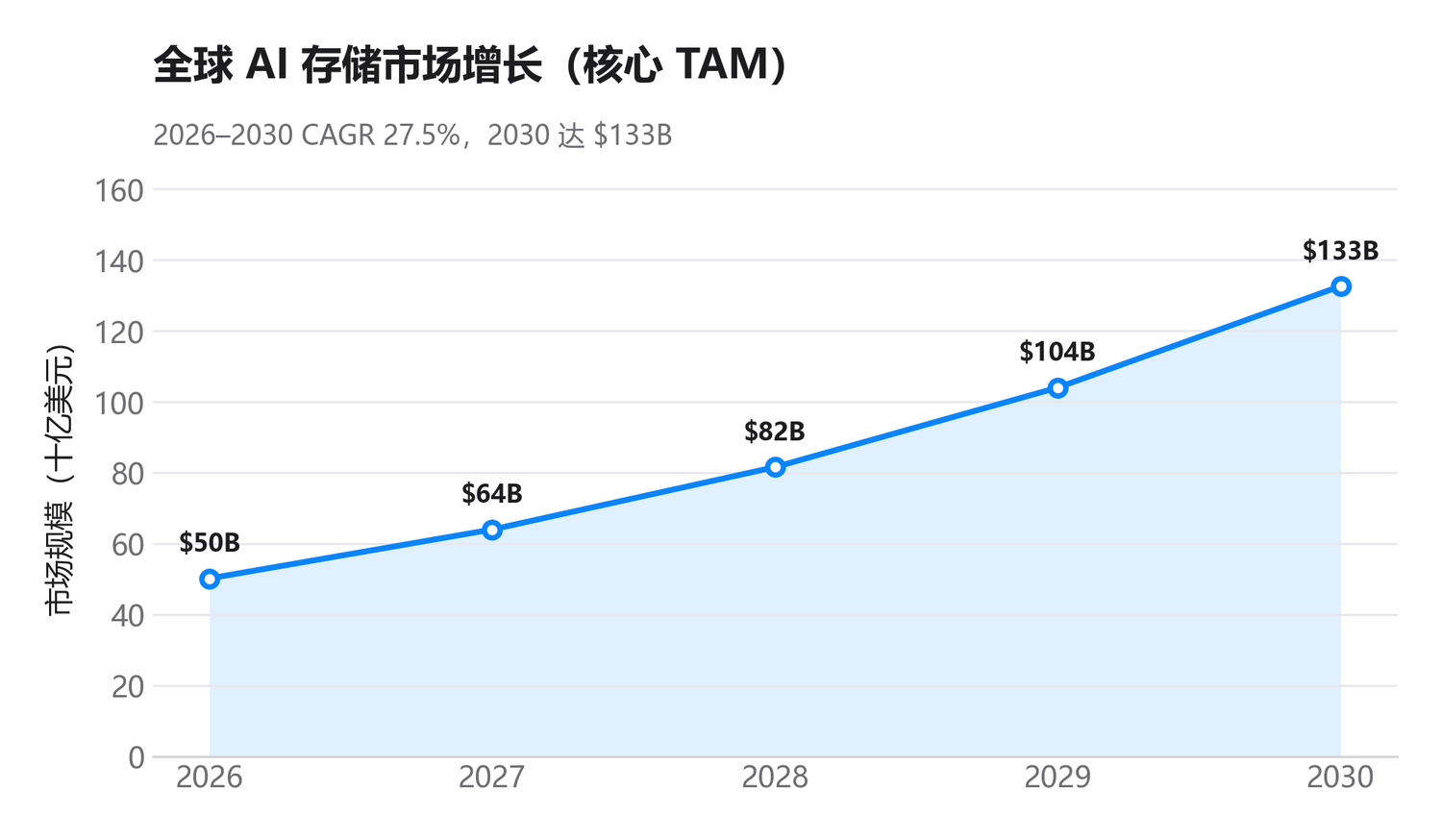
$50B
AI 存储市场 2026
全球口径
$133B
AI 存储市场 2030
全球口径
27.5%
年复合增速
2025–2030
140万亿
中国日均 Token
需求侧锚点
TRAJECTORY
营收路线图(模型测算口径)
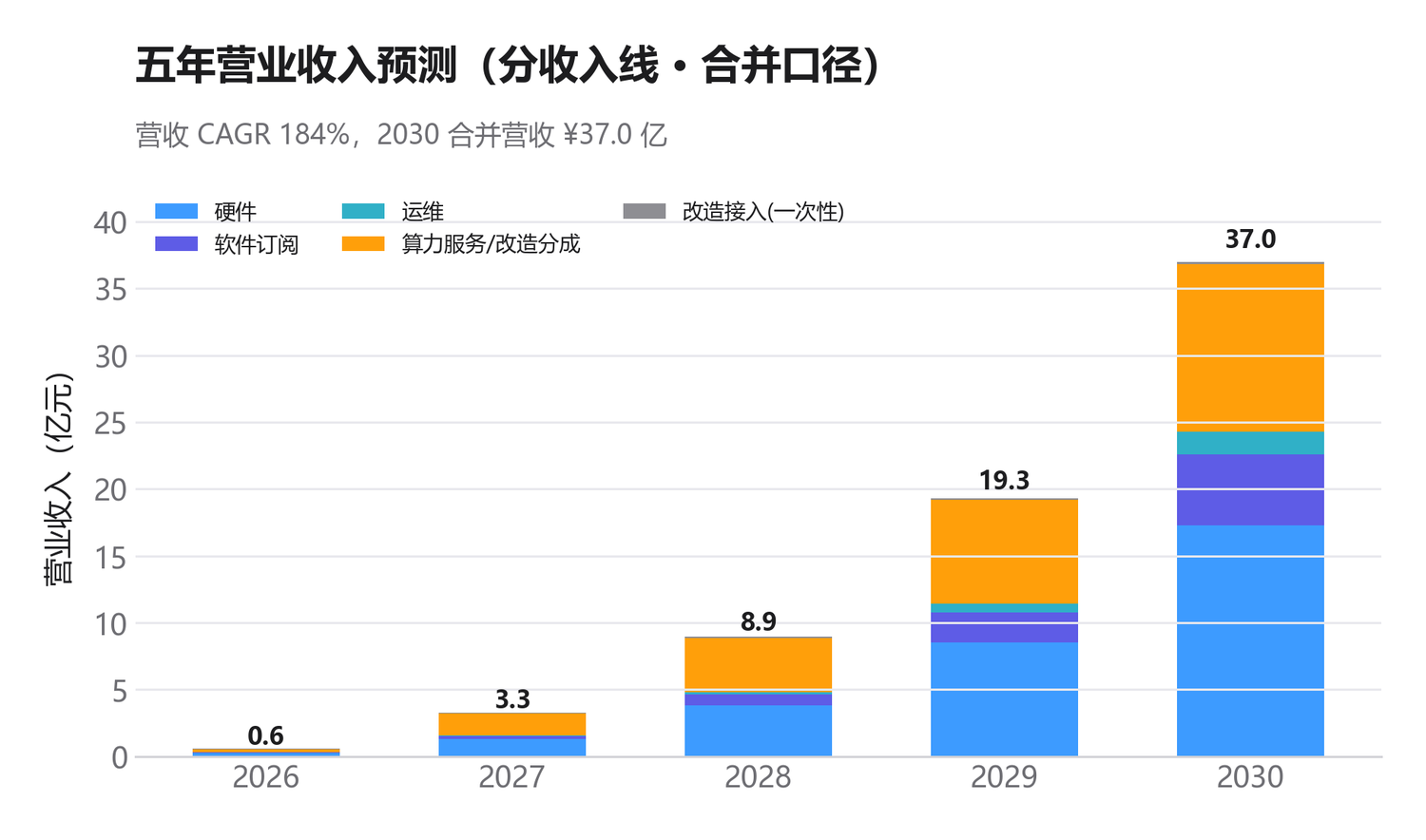
怎么看
在产品已定型量产、第三方验证完成、量产合作落地前提下,2026–2030 营收测算由 0.6 亿 增至 37.0 亿(累计约 69.1 亿);实际经营以最终披露为准。

10
ENABLEMENT
团队赋能与行动
学完能用:目标客户、话术、FAQ 与各角色行动项。
THANK YOU
让每一块 GPU 物尽其用
中科DPU WS5000 · 全闪加速存储算力一体机 · 深圳市中科航星科技有限公司